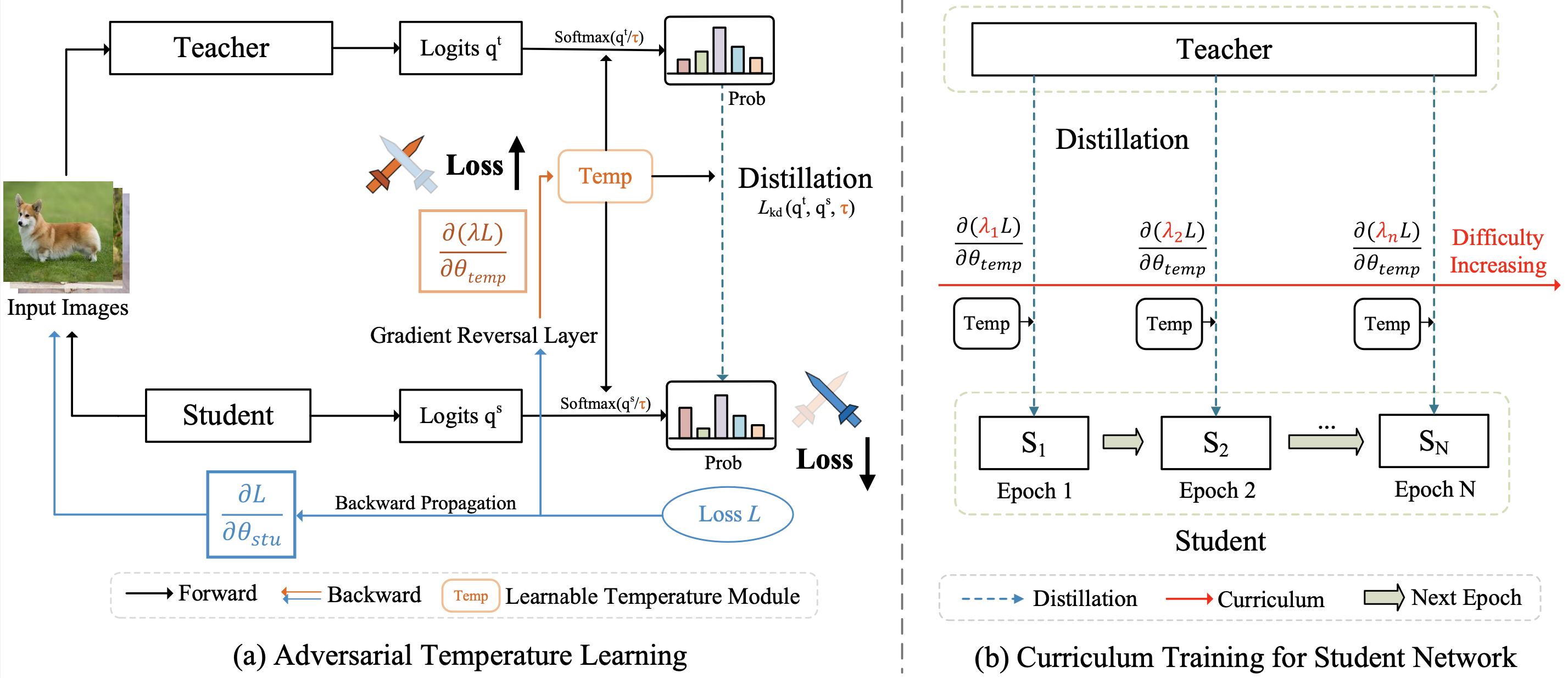
Fig.1 (a) We introduce a
learnable temperature module that predicts a suitable temperature τ for distillation. The gradient reversal layer is proposed
to reverse the gradient of the temperature module during the backpropagation. (b) Following the easy-to-hard curriculum, we
gradually increase the parameter λ, leading to increased learning difficulty w.r.t. temperature for the student.
Abstract
Most existing distillation methods ignore the flexible role of
the temperature in the loss function and fix it as a hyperparameter that can be decided by an
inefficient grid search.
In general, the tempera-ture controls the discrepancy between
two distributions and can faithfully determine the difficulty level of the distillation task.
Keeping a constant temperature, i.e., a fixed level of task difficulty, is usually suboptimal for a
growing student during its progressive learning stages.
In this paper, we propose a simple curriculum-based technique, termed Curriculum
Temperature for Knowledge Disti-llation (CTKD), which controls the task difficulty level during
the student's learning career through a dynamic and learnable temperature.
Specifically, following an easy-to-hard curriculum, we gradually increase the distillation
loss w.r.t. the temperature, leading to increased distillation difficulty in an adv-ersarial manner.
As an easy-to-use plug-in technique, CTKD can be seamlessly integrated into existing knowledge
distillation frameworks and brings general improvements at a negligible additional comp-utation cost.
Contributions
1. We propose to adversarially learn a dynamic temperature hyperparameter during the student’s
training process
with a reversed gradient that aims to maximize the distillation loss between teacher and student.
2. We introduce simple and effective curricula which organize the distillation task from
easy to hard through a dynamic and learnable temperature parameter.
3. Extensive experiment results demonstrate that CTKD is
a simple yet effective plug-in technique, which consistently improves existing state-of-the-art
distillation approaches with a substantial margin on CIFAR-100 and ImageNet.
Method
In this paper, we propose to adversarially learn a dynamic temperature module that predicts a
suit-able temperature value τ for the current training. The temperature module is optimized in the
oppo-site direction of the student, intending to maximize the distillation loss between the student and tea-cher.
Inspired by curriculum learning, we further introduce a simple and effective curriculum which organizes the
distillation task from easy to hard via directly scaling the distillation loss by magnitude w.r.t. the temperature.
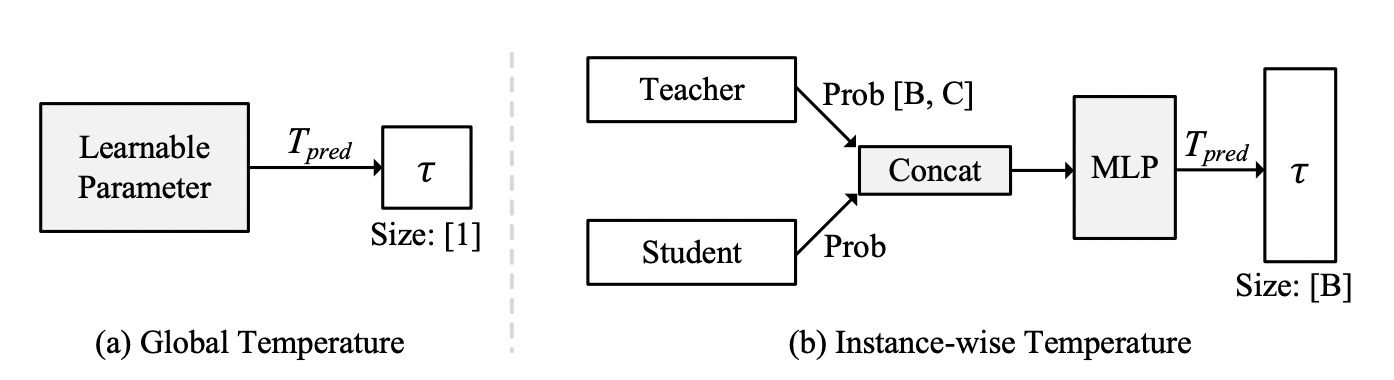
Two versions of the learnable temperature module are used in our approach, namely Global-T and Instance-T,
which respectively generate different forms of temperature for the current training, as shown in Fig.2.
Fig.2 The illustrations of global and instance-wise temperature modules. B denotes the batch size,
C denotes the number of classes. τ is the output temperature.