方法:
既然温度超参τ可以在蒸馏里决定两个分布之间的KL散度,进而影响模型的学习,那我们就可以通过让网络自动学习一个合适的τ来达到以上的目的。
于是以上具体问题就直接可以转化成以下的核心思想:
在蒸馏过程里,学生网络被训练去最小化KL loss的情况下,τ作为一个可学习的参数,要被训练去最大化KL-loss,从而发挥对抗(Adversarial)的作用,增加训练的难度。随着训练的进行,对抗的作用要不断增加,达到课程学习的效果。
以上的实现可以直接利用一个非常简单的操作:利用梯度反向层GRL(Gradient Reversal Layer)来去反向可学习超参τ的梯度,就可以非常直接达到对抗的效果,同时随着训练的进行,不断增加反向梯度的权重λ,进而增加学习的难度。
CTKD的论文的结构图如下:
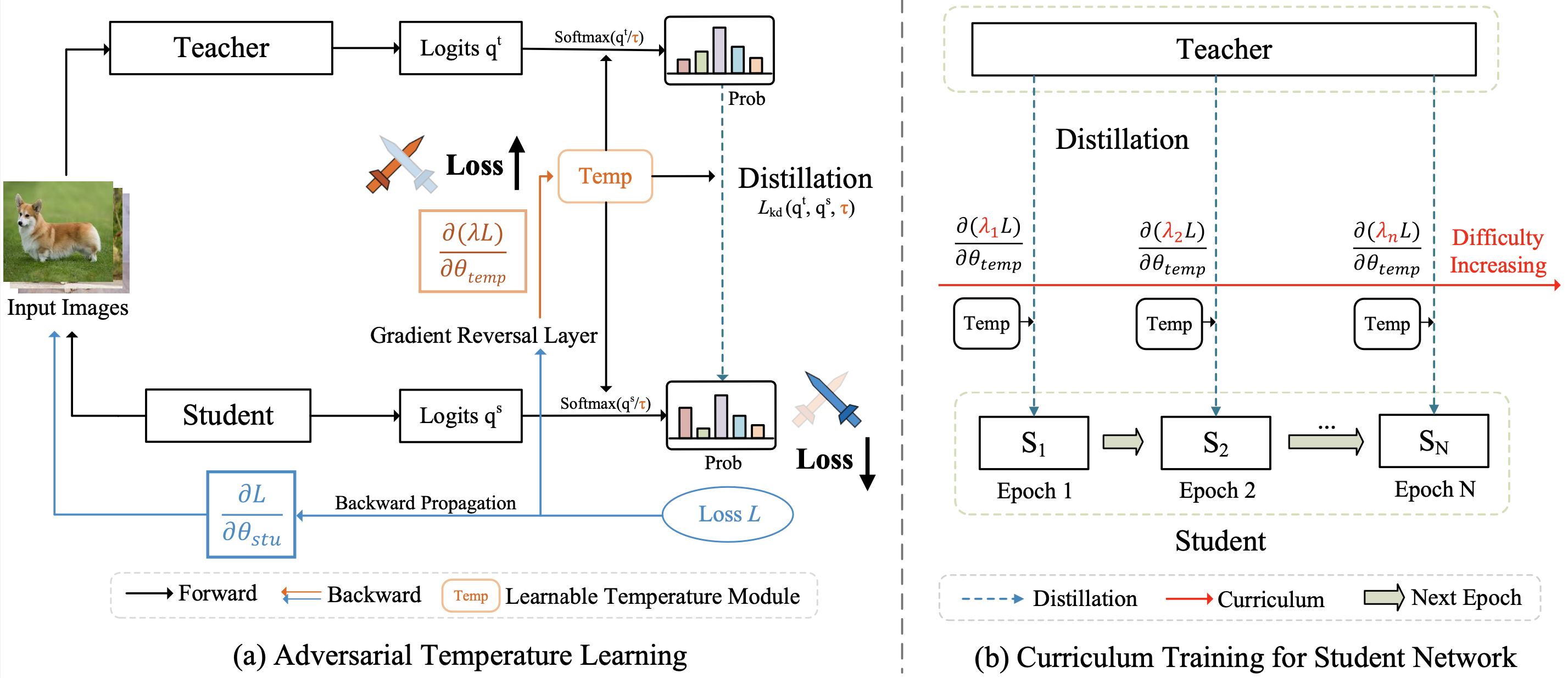
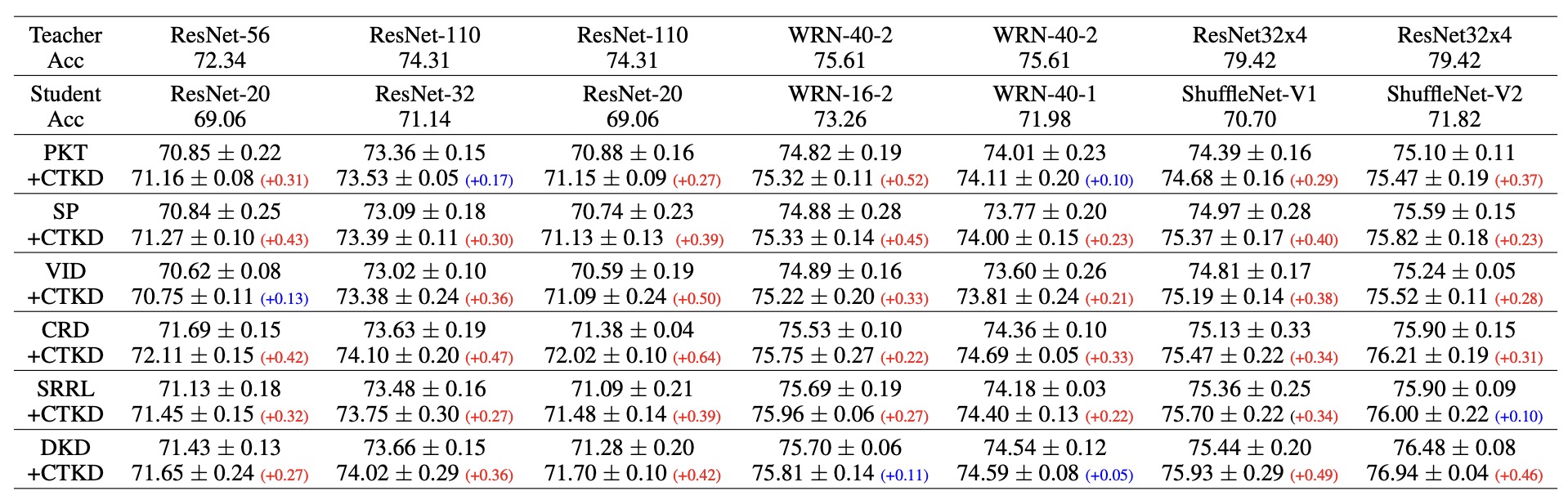
CTKD方法可以简单分为左右两个部分:
1. 对抗温度超参τ的学习部分。
这里只包含两个小模块,一个是梯度反向层GRL,用于反向经过温度超参τ的梯度,另一个是可学习超参温度τ。
其中对于温度超参τ,有两种实现方式:
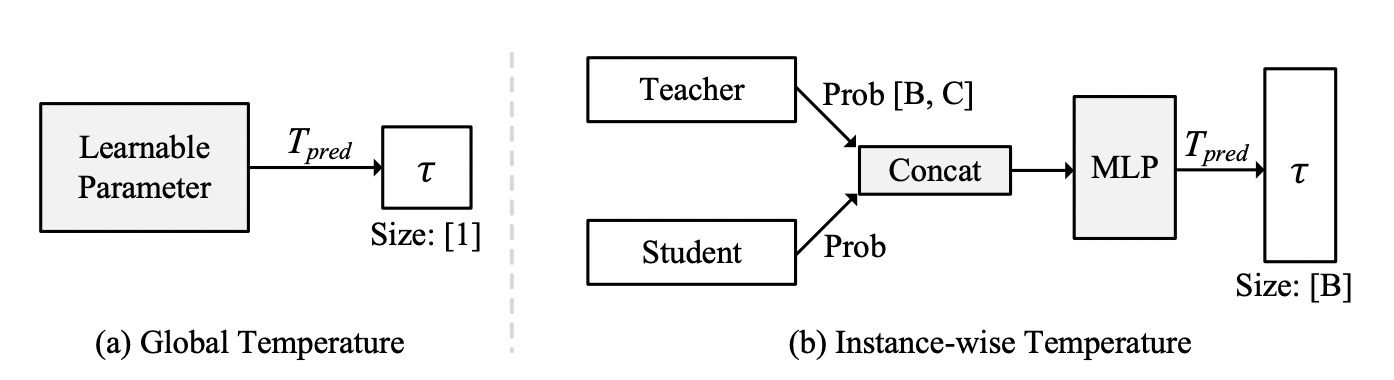
第一种是全局方案(Global Temperature),对于全局只会产生一个τ,代码实现非常简单,就一句话:
self.global_T = nn.Parameter(torch.ones(1), requires_grad=True)
第二种是实例级别方案(Instance-wise Temperature),即对每个单独的样本都产生一个τ,也就是对于一个batch中,如果有128个样本,那么就instance-wise CTKD就会生成对应128个τ。代码实现也很简单,就是两层1x1 conv组成的MLP,将教师和学生的输出concat在一起,送入MLP里面,最后输出128个温度值。
Instance-wise Temp的代码实现已经训练log都已经在GitHub里面提供,在这里。
2. 难度逐渐增加的课程学习部分。
随着训练的进行,不断增加GRL的权重λ,达到增加学习难度的效果,参考图1.(b)中所画。
在论文的实现里,我们直接采用Cosine的方式,让反向权重λ从0增加到1。
以上就是CTKD的全部实现,非常的简单有效。
总结一下方法:CTKD总共包含两个模块,梯度反向层GRL和温度预测模块,
CTKD方法可以作为即插即用的插件应用在现有的SOTA的蒸馏方法中,取得广泛的提升。