一句话概括
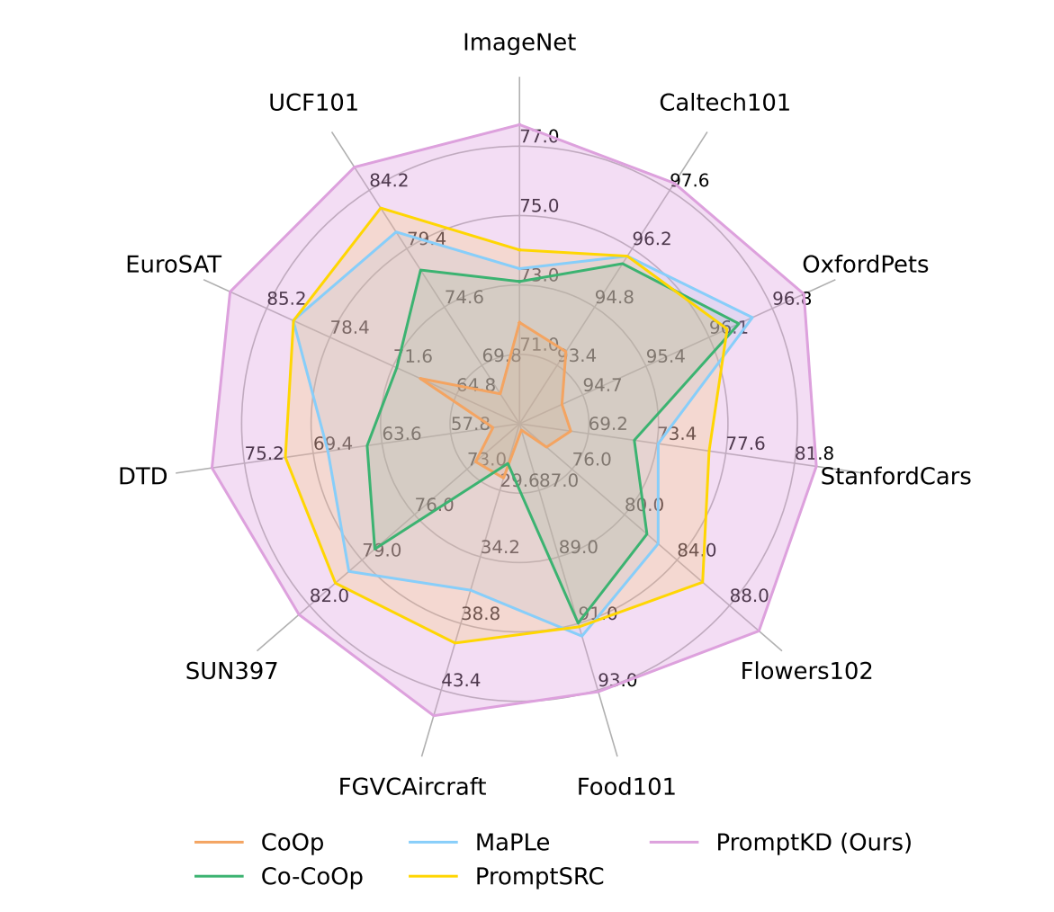
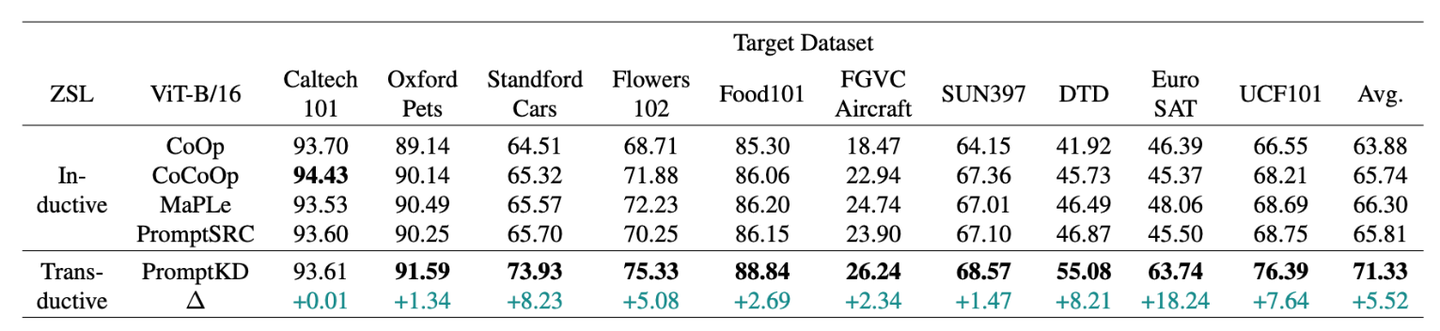
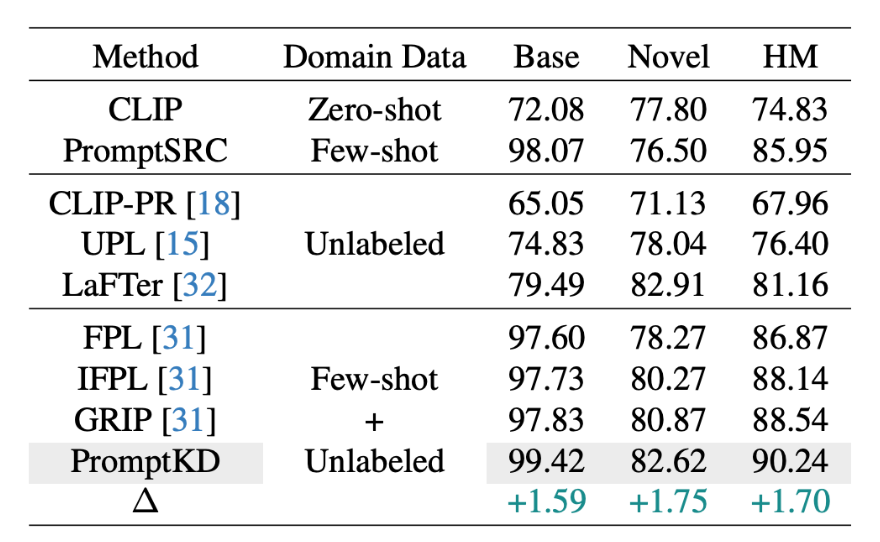
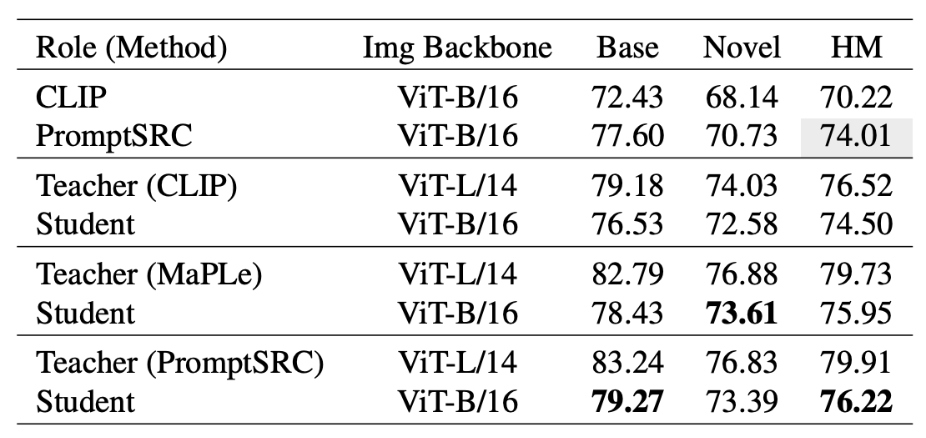
PromptKD是一个简单有效的基于prompt的视觉语言模型蒸馏新方法,在prompt learning的11个benchmark数据集上大幅领先,达到了SOTA。
大白话背景介绍
已经很了解VLMs和prompt learning的同学可以直接跳过,到背景问题~
这里的介绍目的是让没有相关基础和背景的同学也可以看懂这篇工作,能有所收获。
什么是视觉-语言模型(Vision-Language Models, VLMs)?
视觉语言模型VLM一般由两个部分构成,即视觉(Vision)部分和语言(Language)部分。以一个经典的VLM网络 CLIP[1] 的结构为例:
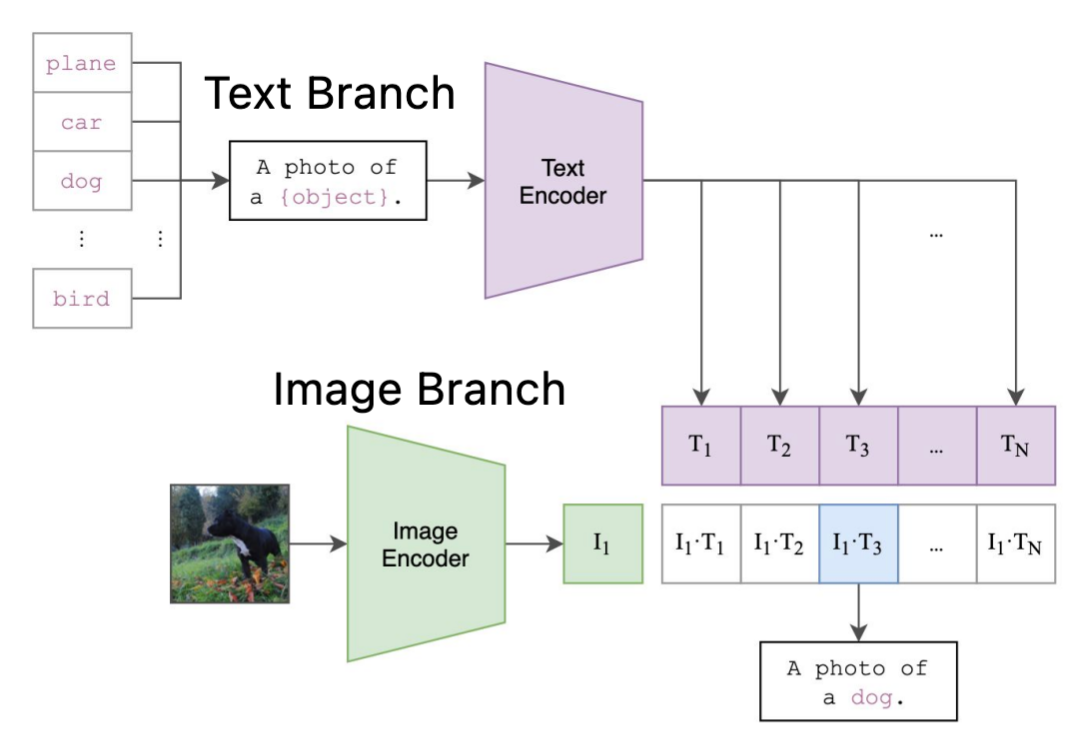
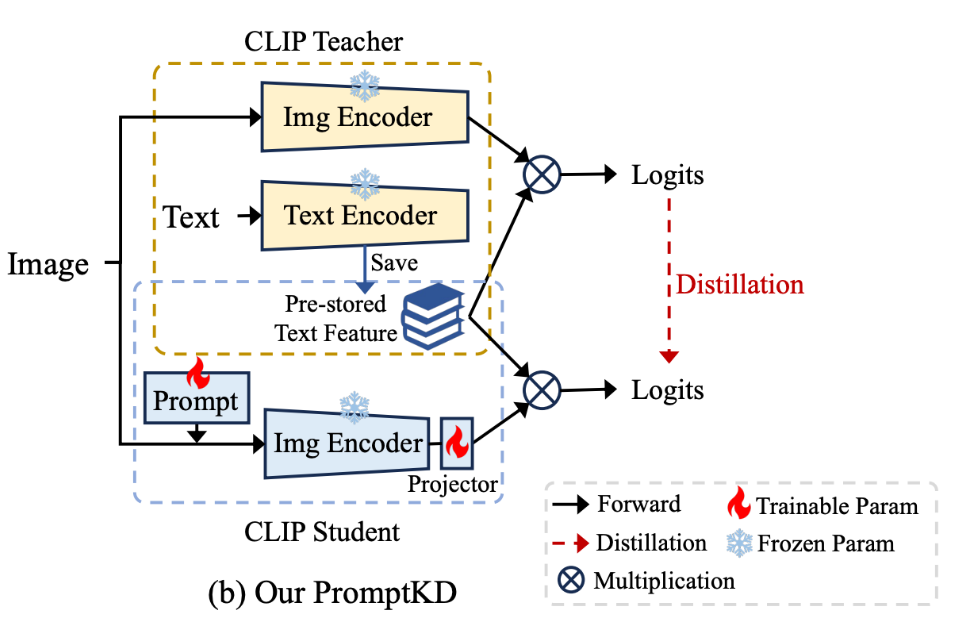
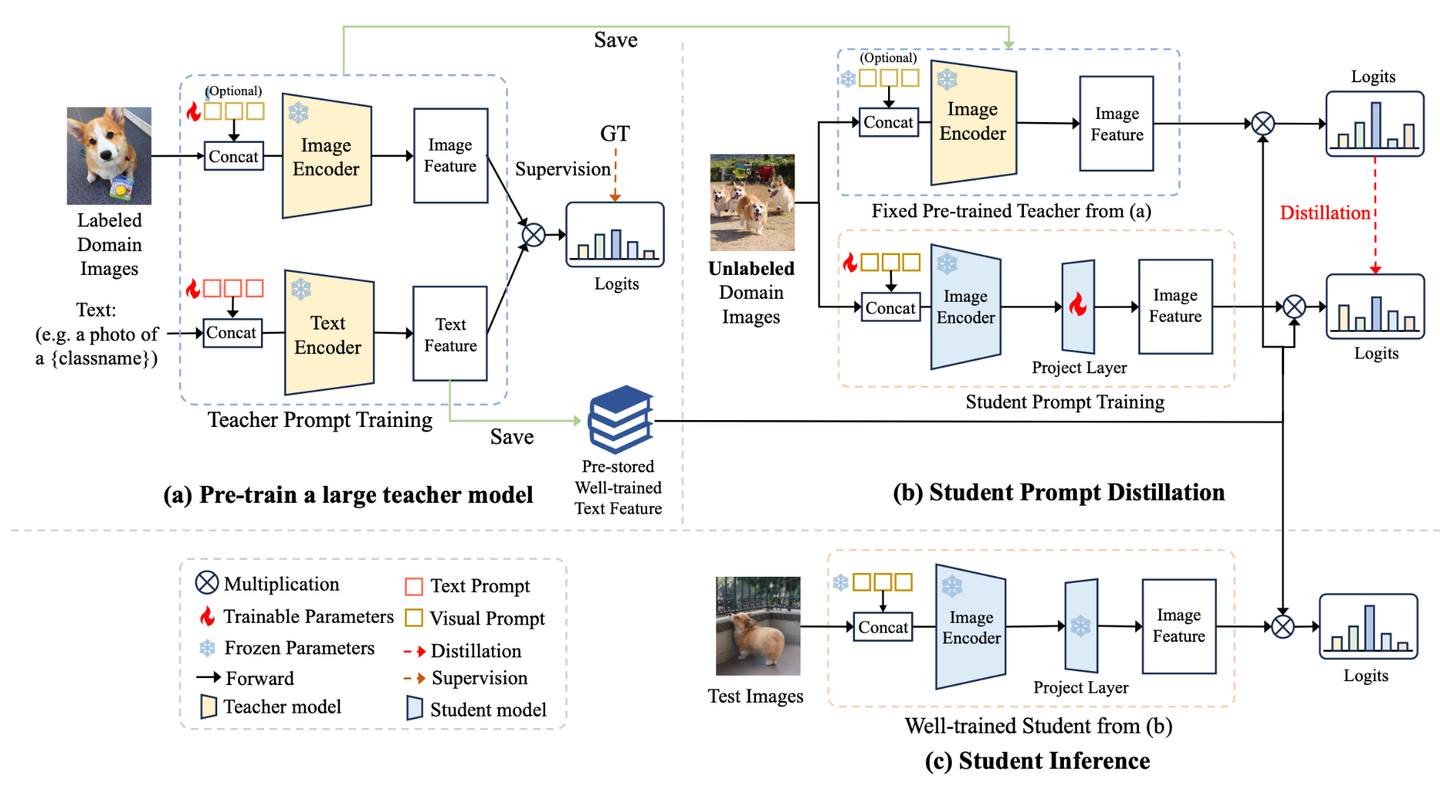
如图1所示,CLIP由text branch和image branch组成。
其中,text branch主要由transformer构成,当要进行cls_num个类的分类任务时,会取每个类别对应的名称,如"plane", "car", "dog",与"a photo of a"进行组合,作为prompt输入进text encoder,得到大小为[cls_num, feat_dim]的text feature。
image branch的核心就是对输入的图像提取image feature,其通常为ResNet或者ViT[2]。图像经过image encoder之后得到image feature,其大小为[batch_size, feat_dim]。
将两个feature进行相乘就得到了预测logits。
CLIP有两个明确的特性,是这个工作的基础:
1. CLIP可以进行zero-shot分类,即对未见过的类别进行识别,并保持很高的性能。而传统的CNN或者ViT由于模型架构限制不可以。
2.对于已知的类别,CLIP的text branch只需要一次forward就可以得到对应text feature用于分类。
什么是提示学习(Prompt Learning)?
在Text Branch部分中,a photo of a {class_name} 这样的描述太过宽泛,明显不是最优的。例如对于图2(b)的花,手工设计的a flower photo a {class}要描述的更加精确,其产生的结果就更好。

这就产生来两个问题,第一,固定模板的prompt不是最优的。第二,针对性的手工设计费时费力,且无法泛化。
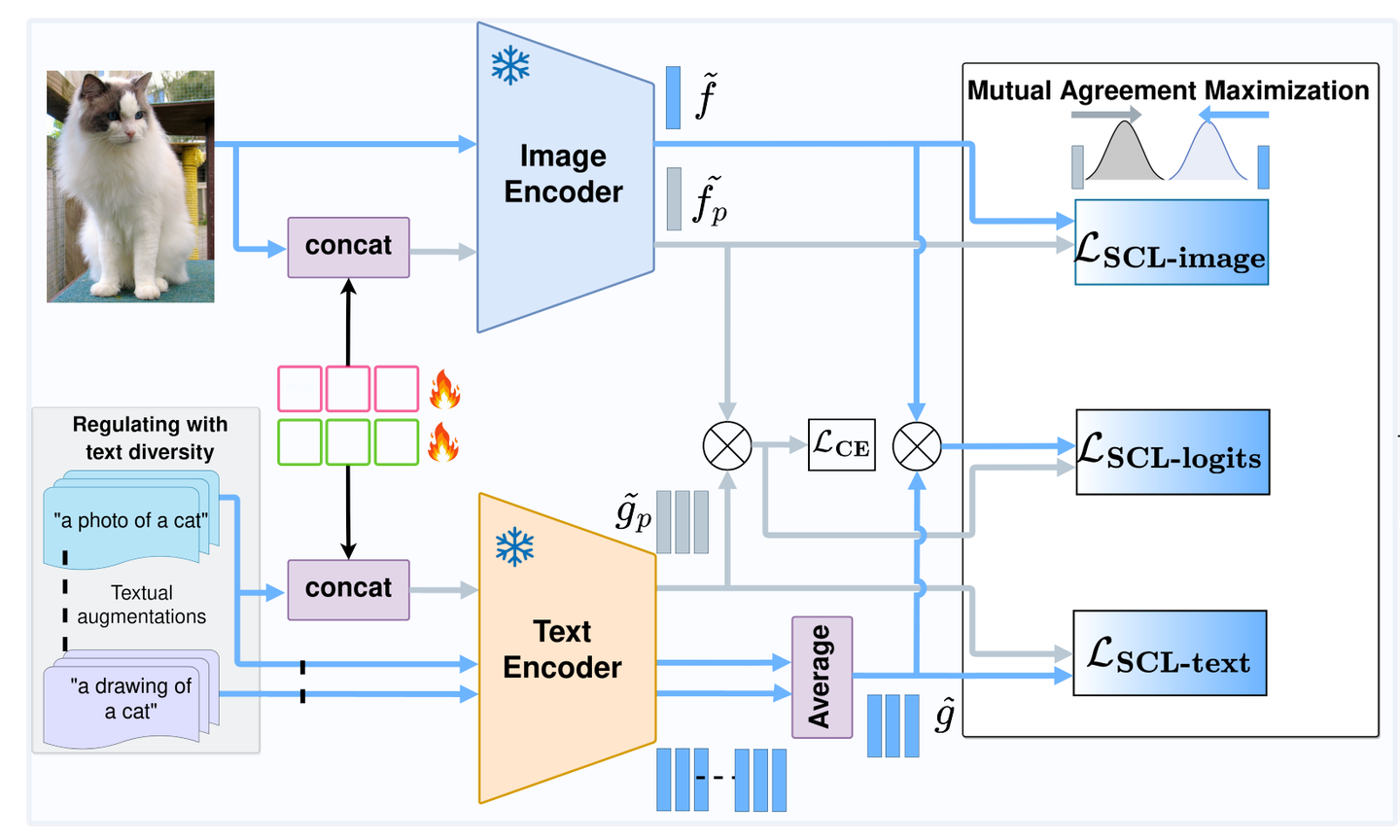
于是,提示学习(Prompt Learning)[3] [4]就提出将prompt变成了一种learnable的方式,通过优化的方法让prompt在下游数据集上学习适用的表征,来替代手工设计的prompt,参考图2中的绿色方块。
这样优势是,可以在少量数据的情况下,仅通过引入一少部分的可学习参数(即learnable prompt),就可以将原始的CLIP快速适用到下游的任务/数据,同时在性能上比全参数微调的结果更好[4]。
实验衡量指标是什么?
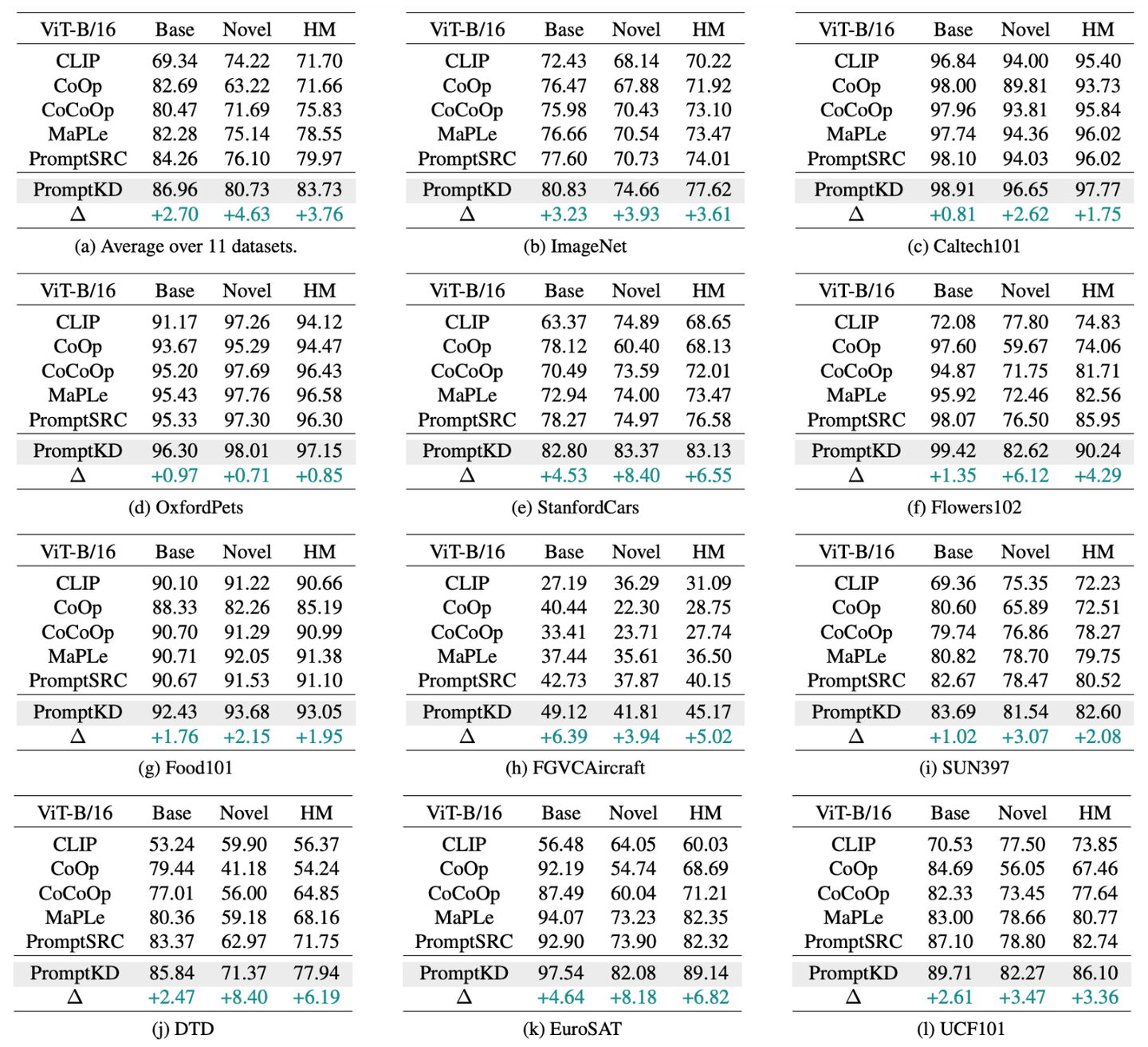
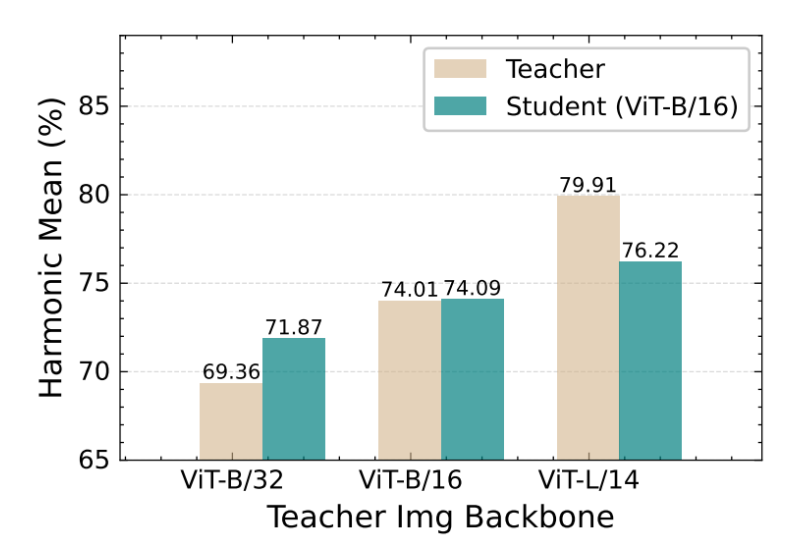
有三个指标,分别是base acc,novel acc和harmonic mean。
以imagenet-1k数据集为例,会取1000类中的前500类作为base class,后500类作为novel class。模型在base class上训练,完成后在base class和novel class上测试acc性能。因为novel class与base class数据类别不重复,所以novel acc可以有效反应模型泛化性能。harmonic mean指标是对base acc和novel acc的综合反映,为harmonic mean = (2*base acc*novel acc) / (base acc+novel acc)。总体的harmonic mean值越高,模型综合性能越好。