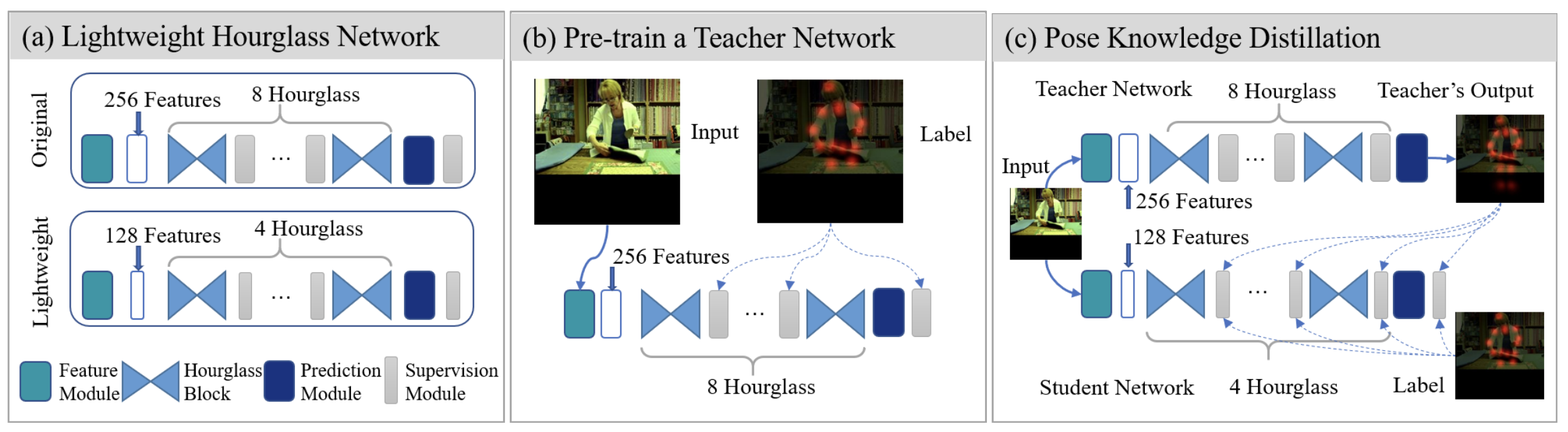
方法:
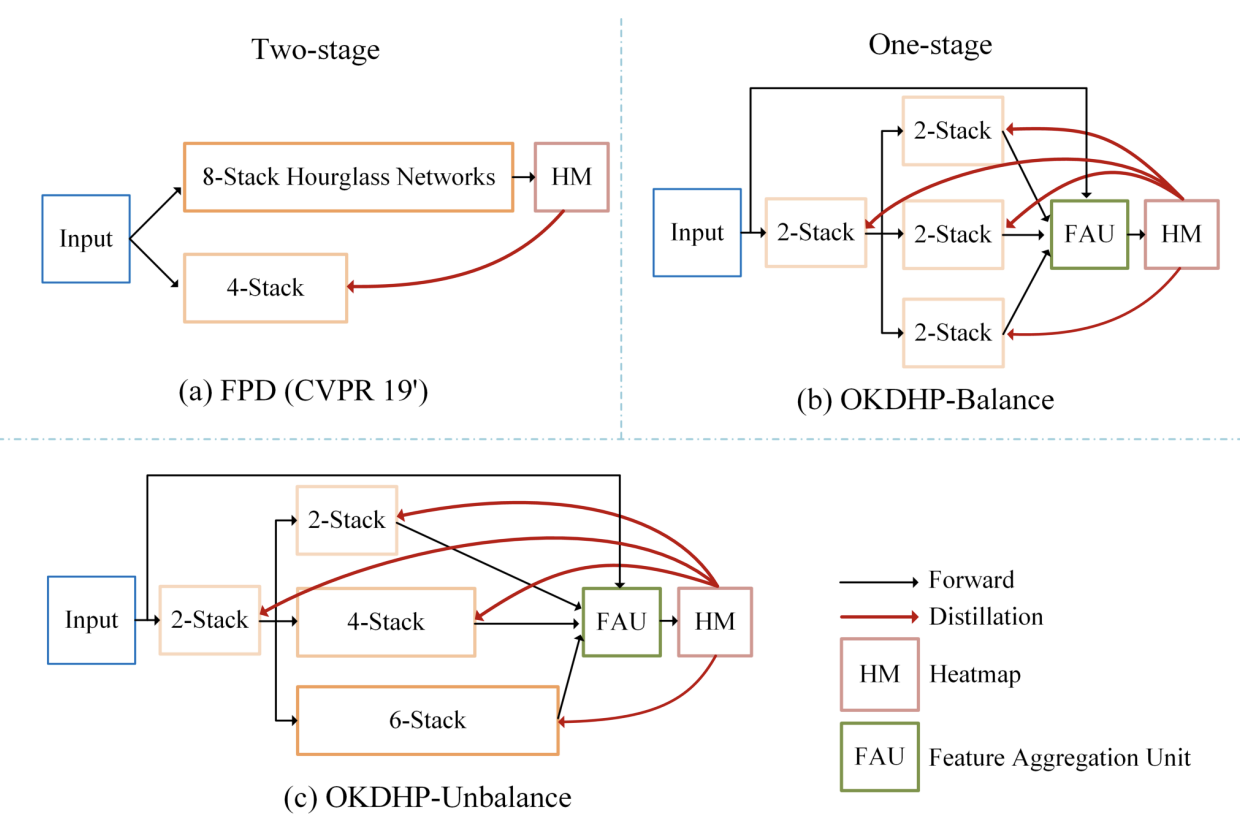
Fig.2 方法结构对比。
由以上的几个问题就引出了我们ICCV 2021的工作,我们首先提出了利用在线知识蒸馏的方法去对网络进行训练。
用大白话来概括一下工作的几个核心:
(1). 我们提出了一个在线知识蒸馏的框架,即一个多分支结构。 这里的teacher不是显式存在的,
而是通过多个学生分支的结果经过了FAU的ensemble形成的,即established on the fly,
我们利用ensemble得到的结果(拥有更高的准确率)来扮演teacher的角色,来KD每个的学生分支,即在Fig.2 (b)中的三个小分支。
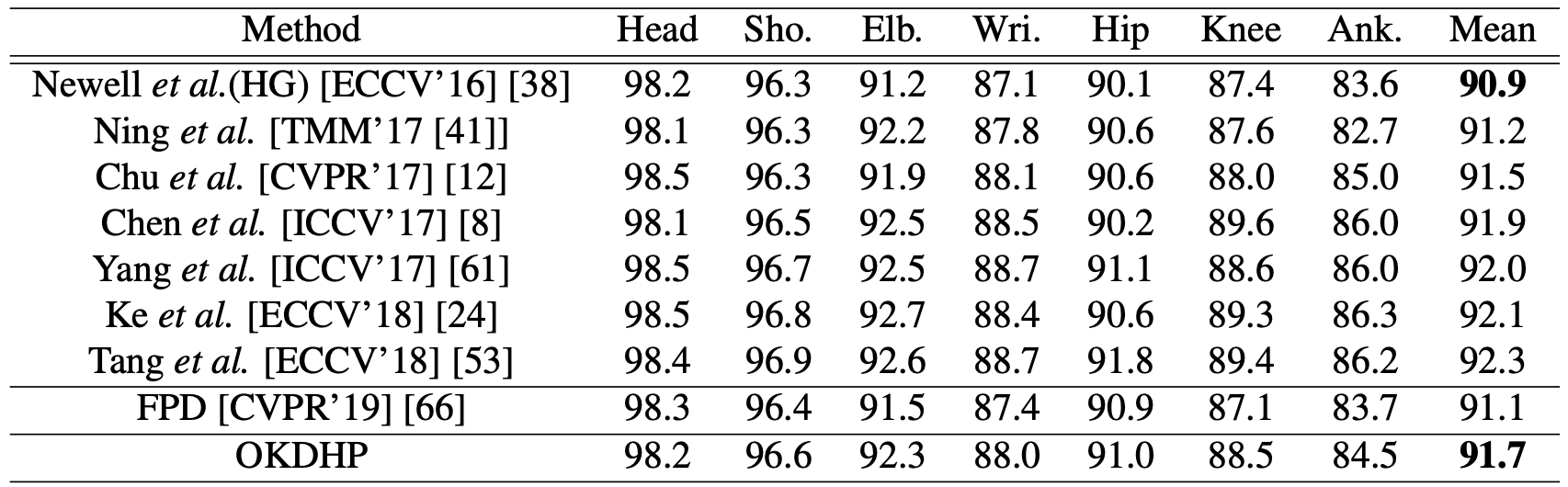
具体来说就是,如果要得到一个4-stack HG的网络,FPD的方式如(a)所示,先训练一个8-stack,然后进行KD。
而在我们的方法,如图(b),直接建立一个多分支网络(图中为3个分支),其中每个分支视为student,
要得到一个4-stack HG,那么我们选择在前部share 2个stack(节约计算量),后面针对每一个branch,
我们将剩下的2个stack HG独立出来,以保持diversity。三个分支产生的结果经过FAU进行ensemble,
得到的ensemble heatmap再KD回每一个student分支。
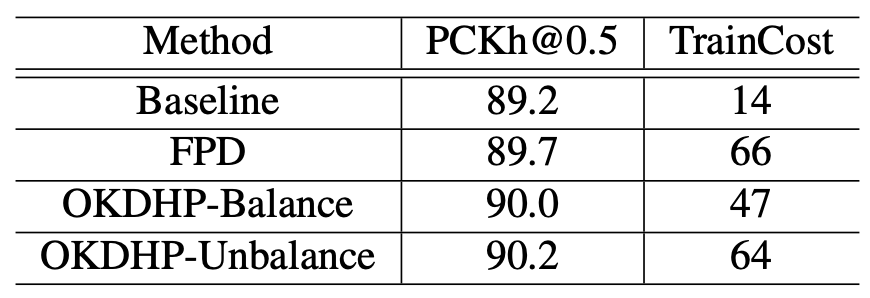
我们的方法带来的直接的好处就是,整个的KD过程被简化到了one-stage,并且不需要手动的选择一个更高performance的teacher来进行KD。
Online KD的方法直接训练完了之后,选择一个最好性能的分支,去除掉其他多余分支结构即可得到一个更高acc的目标HG网络。
那么从这里也可以直接看出我们的多分支网络更省计算量,粗略的算,FPD的方法总共会需要8+4=12个stack参与计算,
我们的方法,只会有2x4=8个stack进行计算。
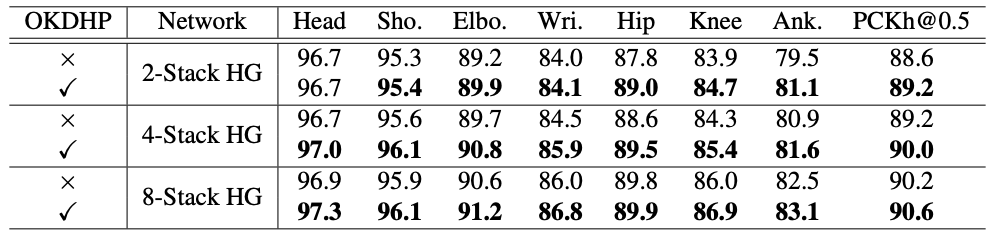
(针对diversity的问题提一下,在OKDDip中就有提及,针对这样的一个多分支模型,每个分支之间的diversity是需要考虑的,
对于每个分支,如果共享的stage过多,那么留给剩下分支的优化空间就会被明显缩小,分支之间在训练的过程中会显式的趋于同质化,
进而带来的结果就是ensemble结果准确率的下降。与之相反,独立的HG数量越多也可以带来KD性能的提升,分支数量同理,
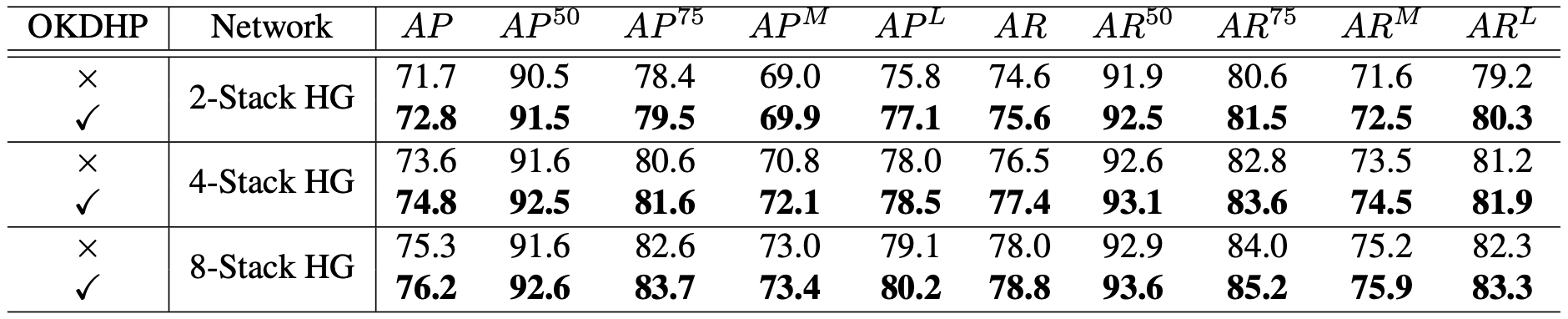
详情请参考paper中的Table 7和8,这里不详细列出。我们在paper中将共享的HG数量设定为目标网络HG数量的一半,
即目标网络8-stack,整个网络就共享4-stack。)
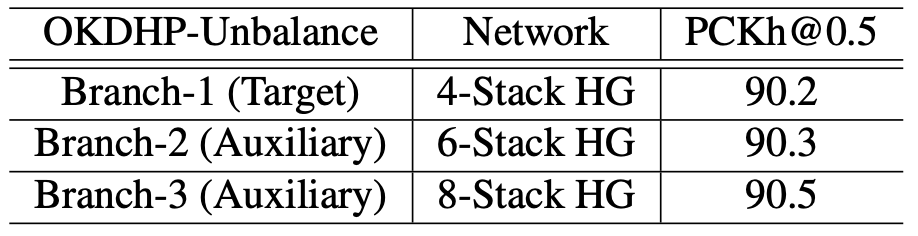
(2). 既然是一个多分支结构,那么每个分支的情况可不可以是adaptive的? 既然在分支里更多的stack可以产生更好的heatmap,
那么必然也就会带来ensemble结果的提升,进而KD的效果就会更好。于是针对(b)的这种每个分支都是一样的balance的结构,
我们更进一步提出了unbalance结构。
具体的来说,要KD得到一个4-stack HG,即Fig.2 (c)中的第一个branch,2+2=4个stack的主分支,
通过在辅助分支堆叠更多的HG来产生更好的ensemble结果,这里就是第二个分支是2+4=6个stack,第三个分支2+6=8个stack的情况。
在不考虑训练计算量的情况下,在部署时移除辅助分支,相比于balance结构,可以得到更好的main branch,即目标的4-stack HG。
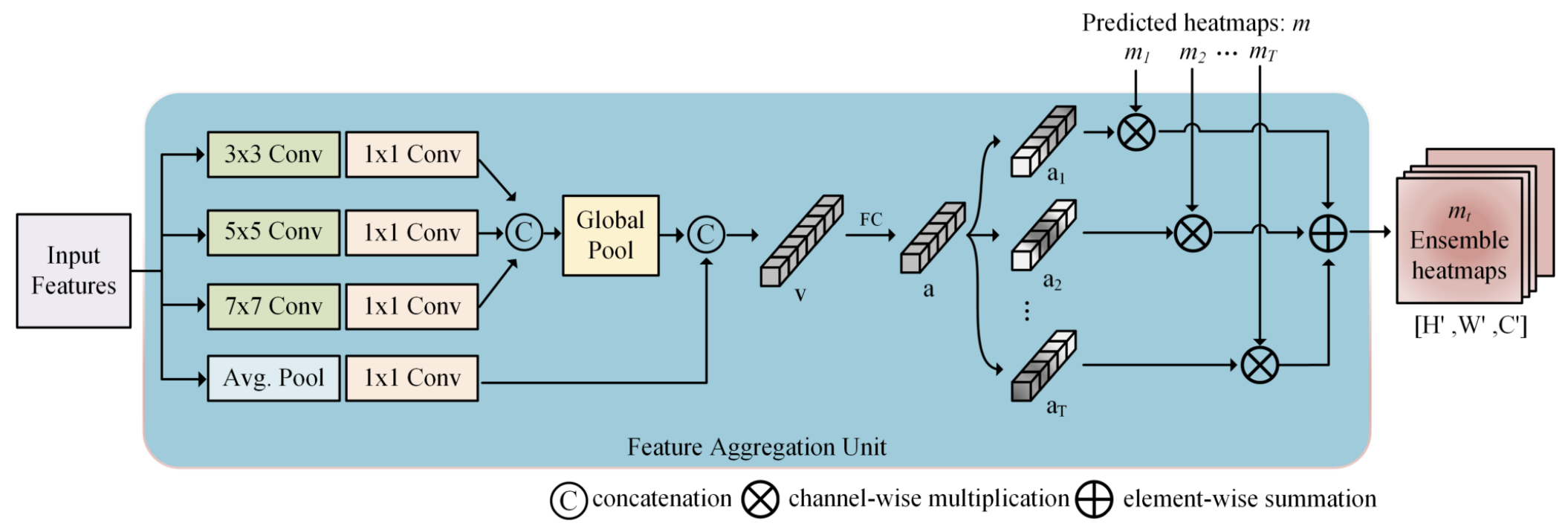
(3). 这里的FAU,即Feature Aggregation Unit,是用来对每个分支产生的结果进行一个带有weight的channel-wise的ensemble。
即将每个heatmap按照生成的权重进行集成。具体的结构如Fig.3所示。
Fig.3 FAU结构。
针对人体姿态估计这种场景下,其实是存在着很多的尺度变化问题,就比如一个人在一张图片中,既可以是贴的很近,占满了整张图片,
也可以是离得很远,只在图片中占小小的一个部分。
受到SKNet的启发,在原先的3x3, 5x5的基础上,
我们拓展出了7x7和avg pool来捕捉更大范围的信息,进而来生成对应每个分支产生的heatmap的weight。
消融实验证明了FAU确实是要比普通的attention方法提高更多。(小声:avg pool这branch我做了实验试了一下,有一丁丁的提升,灰常小)